Building a Library for a Search Engine
Why Build a Library for a Search Engine?
I’m building this library to be used in search engine studies, in small to medium-scale contexts, and to provide an open-source tool where various developers can contribute to its development.
How to Build a Library for a Search Engine
To build this library, I am using as an example this sketch I created after reading the book Recuperação da Informação from the Federal University of Ouro Preto (Sorry for doing it in Portuguese, as it’s just a sketch). In it, I simplified the process to get a general idea of the project.
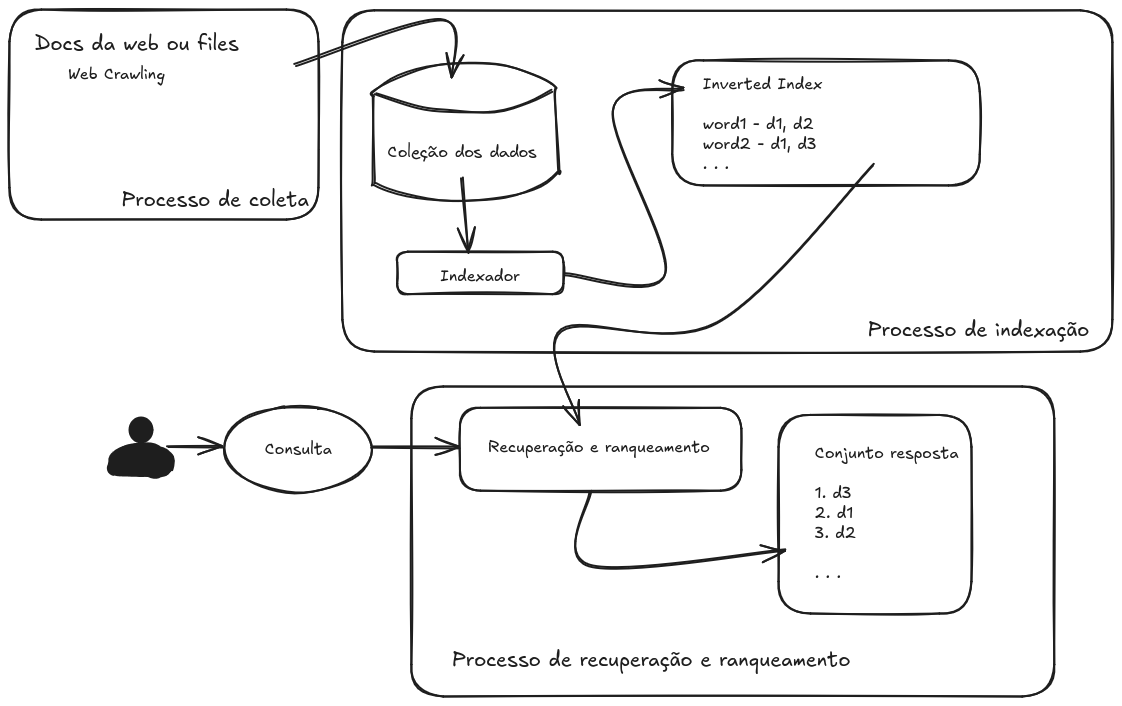 Sketch of the library’s functionality
Sketch of the library’s functionality
To build this type of system, we need a web crawling process that scans a range of pages. After that, we will have a data collection. For this part, I decided to use Python, as it’s much more practical than C++. After that, we will index the files, and for that, we will use the inverted index algorithm, which can be summarized as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
map_str_docs inverted_index::add_doc(map_str_docs& mp, const str& doc_name, str& text) {
shrink_string(&text);
auto words = inverted_index::split(text, DELIMITER);
for(const auto& word : words) {
docs target = {doc_name, 1};
auto it = std::find(mp[word].begin(), mp[word].end(), target);
if(it != mp[word].end()){
*it += 1;
} else {
mp[word].push_back(target);
}
}
return mp;
}
For the structure to store this, I decided to use a std::map<str, std::list<docs>>, as it makes it easier to find the documents. Speaking of documents, I decided to create a structure that will characterize this element, and for that, I used a struct, like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct docs {
str name_doc;
int freq;
list_str links_docs;
bool operator==(const docs& other) const { return (name_doc == other.name_doc); }
bool operator<(const docs& other) const { return name_doc < other.name_doc; }
docs& operator +=(int value) { freq += value; return *this; }
friend std::ostream& operator<<(std::ostream& os, const docs& d) {
os << "Doc: " << d.name_doc << " | Freq: " << d.freq;
return os;
}
};
With these structures, we can put together this initial part.
Key Concepts in Search Engine Development
To create a library, you need to understand and implement the building blocks of a search engine:
1. Inverted Index
An inverted index is the heart of any search engine. It maps each word in the dataset to the list of documents where the word appears. This allows for fast lookups during search queries. My implementation leverages C++ for high performance, with STL structures like std::map and std::list.
2. Ranking Algorithms
Ranking determines how search results are ordered. Algorithms like PageRank or TF-IDF (Term Frequency-Inverse Document Frequency) are commonly used. These algorithms prioritize results based on relevance or importance.
3. Web Crawling
A web crawler fetches and analyzes content from websites to populate your index. In my project, I’ve explored tools like requests and BeautifulSoup in Python for crawling and extracting links.
How I’m Structuring My Library
Here’s how I’ve been building my library step by step:
Creating the Inverted Index I developed a namespace in C++ to handle the indexing process, where each word is mapped to a list of documents and their frequencies. This component is the foundation for search queries.
Integrating Ranking Logic Once the index is built, I plan to integrate ranking algorithms like PageRank. This involves graph traversal techniques, calculating link importance, and scoring pages for better search results.
Building a Python Interface To make the library more user-friendly, I’m exposing parts of the C++ code using Cython. This allows me to write core functionalities in C++ while providing an easy-to-use Python API.
Tools and Languages I’m Using
Here’s a list of tools and frameworks powering my project:
- C++ for core algorithms (inverted index, ranking logic).
- Cython for bridging C++ and Python.
- Python for web crawling and data preprocessing.
- Google Test (gtest) for unit testing.
- LaTeX for documentation and presenting research findings.
Challenges I’m Facing
Every project has its hurdles. Some challenges I’ve encountered include:
- Memory Optimization: Handling large datasets efficiently while keeping the performance optimal.
- Interface Design: Making the library intuitive and flexible for other developers.
- Algorithm Scalability: Adapting the ranking algorithms to handle diverse and dynamic datasets.
What’s Next?
Currently, in the Search Engine project, I am implementing the inverted index. As of the date of this post, I have already implemented the connection to Cython, and it can now be used in Python. However, I still need to implement TF-IDF and various other ranking methods, as well as a structure that can be used in research projects. In the future, I want to integrate AI into this project, which is why part of it is using Python, so I can make that connection later.
References
Here are some key references that have been guiding my project:
- Christopher D. Manning, Prabhakar Raghavan, and Hinrich Schütze - Introduction to Information Retrieval. A classic textbook covering the foundations of search engine design, information retrieval, and text processing.
- Recuperação da Informação - Published by the Programa de Pós-Graduação em Engenharia de Produção da Universidade Federal de Ouro Preto (PPGEP-UFOP) - ICEA/DEENP. This resource provides a comprehensive perspective on information retrieval tailored to academic and industrial applications.
Conclusion
I am still in the early stages of the project. Some steps have already been completed, but they still need polishing and better organization. I am very excited to develop it and also for other programmers to contribute to the project in the future. I hope this tool will help in research about simpler search engines, providing a solid foundation for studies and improvements in the field.
Keep learning,
Pedro;)